When you start working with Kubernetes (K8s) there’s a lot of new terminologies to learn, understand and then remember. Wouldn’t it be great if instead of having to search for a definition every time you came across a word you weren’t familiar with, you could access all of the key Kubernetes terminology in a single list?
We’ve got you covered! This glossary contains explanations for all of the common technical terms you’ll need to understand Kubernetes.
Introduction
Before we get into what someone actually means when they say “Can you just specify taints and tolerations on the pods and nodes then set up a cronjob to run every 5 minutes?” it is worth recapping a few terms that aren’t specific to Kubernetes but are vital for understanding it.
If you’re already familiar with Kubernetes, then feel free to skip straight to the main glossary…
Microservices
Microservice architecture is a method for structuring and developing applications. Rather than having a large, monolithic application where all of the features are interdependent, the application is broken down into a collection of smaller services (conveniently named microservices).
Each microservice can be deployed independently of the rest of the application. For example, an online retailer could have one microservice for inventory management and another controlling their shipping service.
The key point to remember is that before you can take advantage of Kubernetes, your applications need to have a microservice architecture.
Containers
A container is a standardised structure which can store and run any application. Originally containers were simply considered as an alternative to Virtual Machines (VMs) when it came to virtualisation technology, but now, they are often the “go-to” for virtualisation.
So you’ve re-architected your application into microservices. Now each microservice can be stored in its own container, along with everything it needs to run (settings, libraries, dependencies etc.). This creates an isolated operating environment so the container can run on any machine.
Docker
If you’ve heard of containers then you’re almost certainly going to have come across Docker too. Docker is the industry-leading containerisation technology, currently possessing ~95% market share.
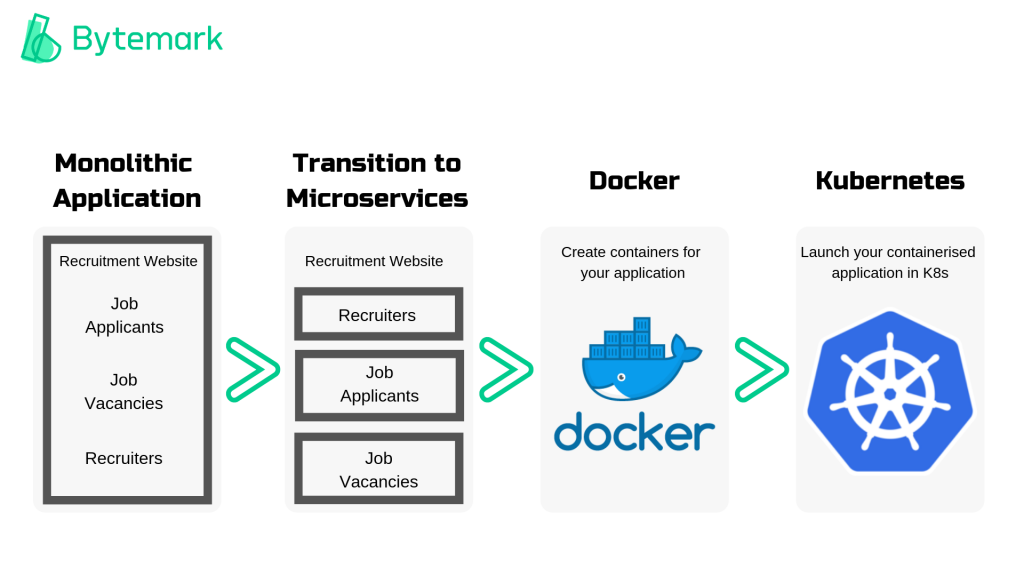
Sometimes, there is an initial confusion about how Docker and Kubernetes relate. Docker is not an alternative to Kubernetes. The two technologies are used together. Docker allows you to “create” containers and Kubernetes helps you to “manage” containers.
Completely new to Kubernetes? You can also read our Beginners’ Guide for more background on the definition, purpose, architecture and benefits.
Now that we’ve got the introductions out of the way, let’s get into the terms that are more specific to Kubernetes!
The Basics
Before you start actually using Kubernetes or trying to understand the architecture behind how the tool works, there are seven commonly used terms which it is worth fully understanding first.
Pod
A pod holds one or more container(s). Pods are the simplest unit that exists within Kubernetes (this is why containers technically aren’t a part of Kubernetes – as even a single container is called a pod).
Any containers in the pod share resources and a network and can communicate with each other – even if they are on separate nodes.
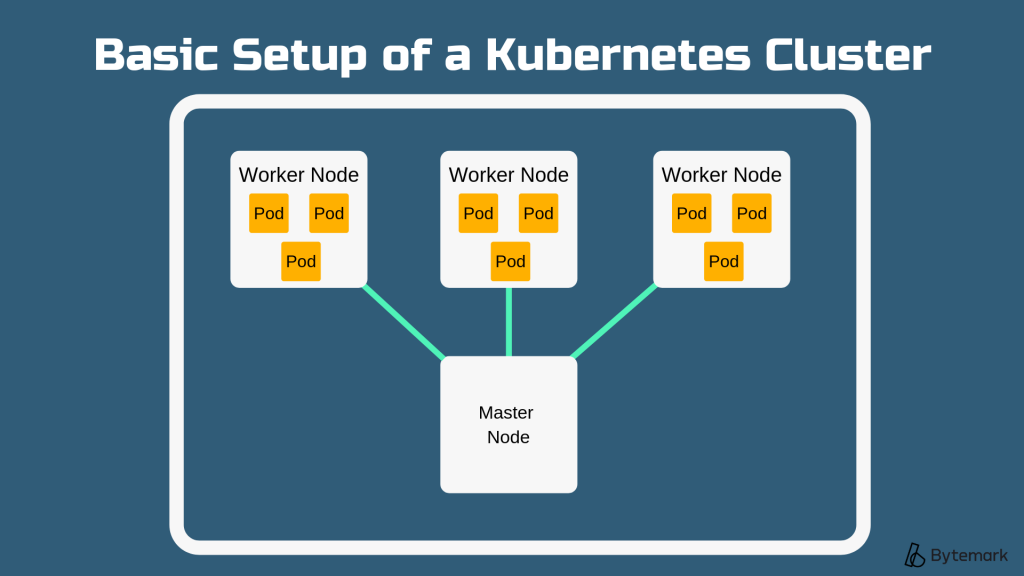
Node
Nodes are the hardware components. A node is likely to be a virtual machine hosted by a cloud provider or a physical machine in a data centre. But, it can simpler to think of nodes as the CPU/RAM resources to be used by your Kubernetes cluster, rather than just as unique machines. This is because pods aren’t constrained to any given machine at any given time, they will move across all available resources to achieve the desired state of the application.
There are two types of node – worker and master.
Cluster
Clusters actually run the containerised applications being managed by Kubernetes. A cluster is a series of nodes connected together.
By joining together, the nodes pool their resources making the cluster much more powerful than the individual machines it is made up of. Kubernetes moves pods around the cluster as nodes are added/removed.
A cluster contains multiple worker nodes and at least one master node.
Services
A service is an API object that exposes an application, it essentially describes how network traffic should access a set of pods. Services are found on every node.
Deployment
Deployments are an API object, they essentially manage pod replication.
A deployment defines the state of your cluster – for example, how many replicas of a pod should be running. When the deployment is added to a cluster, Kubernetes will automatically make the correct number of pods and then monitor them. If a pod fails, Kubernetes will replicate it, following the ‘deployment’ criteria.
Kubeadm
Kubeadm is a quickstart installation tool for Kubernetes.
It helps you to create a minimum viable cluster with a single master node. Kubeadm is quick and simple to use. Plus, it makes sure your cluster conforms to best practices so it is a great tool to use when trying out Kubernetes for the first time or for testing your applications.
Minikube
Minikube is a lightweight version of Kubernetes which is much easier to use locally. It will create a VM on your local machine where you can run a single-node cluster. This is useful for testing.
Architecture & Main Components
The core Kubernetes architecture consists of the worker nodes, the master nodes and the Kubernetes API. This section will define these core parts, as well as some of the main components within them.
Worker Node
Worker nodes are where pods are deployed.
Kubernetes has a master-slave architecture, so a worker node is a slave.
Kubelet
Kubelet is an agent that runs on every worker node in a cluster. This is an important component because it receives the instructions from the master node.
The kubelet essentially runs the pods. It ensures that all containers are running in a pod and that these pods are healthy and running at the correct points in time. So it will launch and kill pods as it receives instructions from the master node regarding which pods need to be added or removed.
kube-proxy
kube-proxy is the Kubernetes network proxy. It is a service that runs on every node and handles request forwarding.
The main job of kube-proxy is setting up iptables rules. This deals with the fact that different pods will have different IP addresses and allows you to connect to any pod within Kubernetes, this is important for enabling load balancing.
If you’re looking for a bit more technical detail, it proxies UDP, TCP and SCTP but does not understand HTTP.
Master Node
Master nodes control the deployment of pods, and therefore the worker nodes.
As the name suggests, in the master-slave Kubernetes architecture, these nodes are the master.
Etcd
etcd stores configuration information for large, distributed systems.
So Kubernetes uses etcd as a key-value store for configuration management and service discovery. Etcd must be highly available and consistent to ensure services are scheduled and operated correctly. As etcd’s data is so crucial, it is highly recommended that you have a backup for your cluster.
Scheduler (kube-scheduler)
The scheduler is a component on the master node and it does what it says on the tin – makes scheduling decisions for newly created pods.
When a pod is created it must be assigned a node to run on. The scheduler receives information from the API about the pods’ requirements and specifications and the IT resources on available nodes. It will then assign each pod to an appropriate node. If the scheduler cannot find a suitable node, the pod remains unscheduled and the scheduler retries the process until a node becomes available.
Controller
A controller is a component on the master node, it works to move the application from its current state towards the desired state.
Kubernetes has a variety of controllers. For example, the ReplicationController makes sure that the correct number of pod replicas are running at any given time. The controller will ‘watch’ the API for information about the cluster state and make changes accordingly.
So, if the API specified that there should be 7 replicas of podA, but there was currently 8, the ReplicationController would terminate the extra pod.
kube-controller-manager
This is a component on the master node that manages all of the controllers.
Each controller e.g. ReplicationController, NamespaceController etc. is actually a separate, individual process. However, to simplify cluster management, they are all compiled into a single process. The kube-controller-manager is responsible for this compilation.
It’s also a way to add cloud-vendor specific functionality to clusters. This helps to keep Kubernetes vendor-agnostic.
kube-apiserver
kube-apiserver is a component on the master node which reveals the Kubernetes API to the master.
It essentially acts as the frontend to the information on the cluster’s shared state, providing a bridge between the API and other Kubernetes objects e.g. pods, controllers, services etc. So all interaction between components goes through the kube-apiserver.
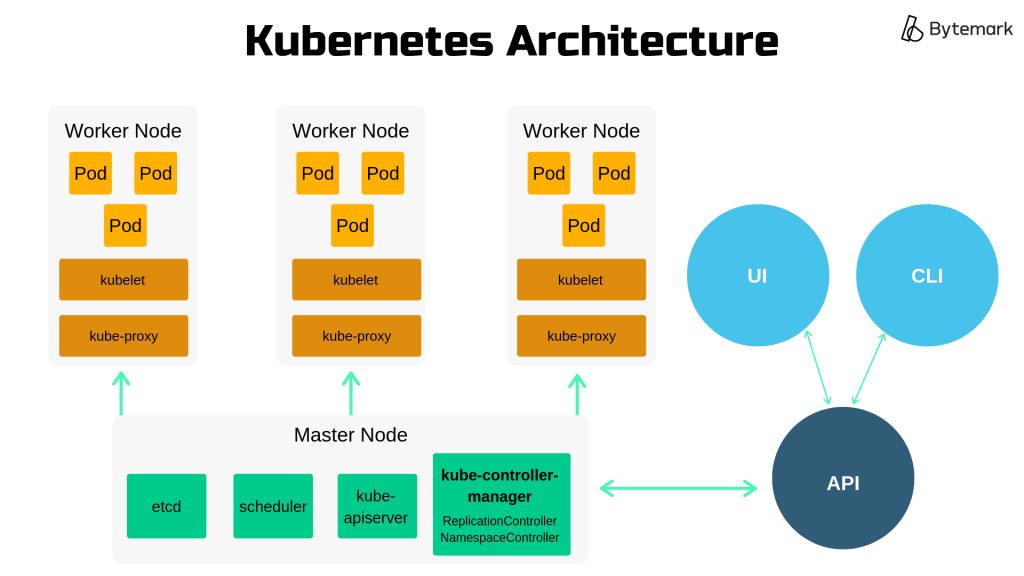
Kubernetes API
The API enables Kubernetes to function. It stores information about the state of the cluster.
Information about the desired state of the cluster is inputted to the API via a user or command line interface. The Kubernetes API then passes this information onto the master node. The master node will then instruct the worker nodes to carry out actions that drive the application from its current state towards the desired state.
Kubectl
Kubectl is the official Kubernetes command line interface tool. It is used to communicate with the API.
You can input command to kubectl to create, inspect, change, replicate and destroy Kubernetes objects e.g. pods and nodes.
Aggregation Layer
The aggregation layer allows you to extend Kubernetes by installing additional APIs.
This can provide greater functionality than using just the core Kubernetes API. For example, you can add API extensions which allow you to define new controllers.
Identification & Organisation
A single Kubernetes cluster can scale to contain up to 5,000 nodes and 150,000 pods. That results in a lot of objects to be managed. So, besides some of the core components that we covered in the ‘Architecture and Components’ section, there is a wide range of other components that function to help identify and organise the different Kubernetes objects.
Name
Names are unique identifiers for Kubernetes objects, they are client-provided. Only one object can have a specific name at any given time. However, if that object is deleted you can then create a new object using the same name.
Names refer to an object in a resource URL e.g. /api/v2/pods/test-name. They can be up to 253 characters and can contain lowercase alphanumeric characters, “.” and “-”.
UIDs
UIDs are unique identifiers for Kubernetes objects, they are systems-generated. Unlike with names, every object created over the lifetime of a Kubernetes cluster has its own UID. So, even if you delete an object you can’t then reuse the same UID when you create a new object.
Here is an example of a UID: 946d785e-998a-12e7-a8dd-42010a800007, because they are systems-generated they are typically less user-friendly than names. But, the fact they are only ever used once makes UIDs useful for distinguishing between historical instances of similar objects.
Annotations
Annotations are key-value pairs which are used to attach non-identifying metadata to Kubernetes objects.
Labels
Labels are key-value pairs which are used to attach meaningful, identifying metadata to Kubernetes objects.
 What is the difference between labels and annotations? In short, if you want to include data that will help people or other tools, but not Kubernetes directly, then you should use annotations. Whereas, if you want to include specific identifying information which can be used to organise or select subsets of objects, then you should use labels.
What is the difference between labels and annotations? In short, if you want to include data that will help people or other tools, but not Kubernetes directly, then you should use annotations. Whereas, if you want to include specific identifying information which can be used to organise or select subsets of objects, then you should use labels.
For example, after you’ve released updates to your application, you could use annotations to record release information e.g. timestamps or git branches which may be helpful for other developers. You could also apply a “version” label to identify the current version of the application running on each resource object. This would then allow you to organise objects into groups based on which version of the application they were using.
Selector
Selectors are used to querying Kubernetes resources and filter them by their labels. A selector allows you to identify a set of objects with shared characteristic(s).
There are equality-based selectors, which allow you to identify all resources that possess a certain label. For example, “environment = dev” would filter a list of all resources that are running in a dev environment.
There are also set-based selectors, which allow you to identify all resources that match a set of values. For example, “environment in (production) tier notin (backend)” would provide a list of all resources in a production environment, excluding any labelled as backend.
Pod Preset
PodPreset is an API object that automates the addition of information to pods as they are created.
The PodPreset uses selectors to determine which pods should receive which information. You can add information such environment variables, secrets (service account ‘credentials’) and volumes using PodPreset.
This object saves time, as pod template authors don’t have to provide all information for each pod. It also has benefits for access control, as it means authors also don’t need to know all of the details about specific services on a pod.
Role-Based Access Control (RBAC)
RBAC allows Kubernetes admins to configure access policies through the API. It allows you to assign different roles to users which gives them varying permissions.
If you’re familiar with WordPress blogs, RBAC works in a similar way. The functions you can perform within Kubernetes depends on the permissions level your role allows. Just like how in WordPress an Author can post new articles, but can’t update existing ones. Whereas an Editor both publish new articles and edit existing ones.
Service Account
Service accounts are used to identify processes that run in a pod. All pods have a service account, if you do not set a specific service account for a pod then it will be set to default.
Service accounts are similar to a user account that you have to log into a website. You can only access the website if your user account has the necessary credentials to successfully log in. In the same way, a process in a pod can only run if it is authenticated by the API to access cluster resources. The Kubernetes API will only authenticate the process if the service account provides the necessary credentials.
Container Environment Variable
Container environment variables are name-value pairs which provide meaningful information to the containers running in a pod.
This information can be about the container itself or about resources which are important for running the containerised application. An example would be details of the pod IP address or file system details.
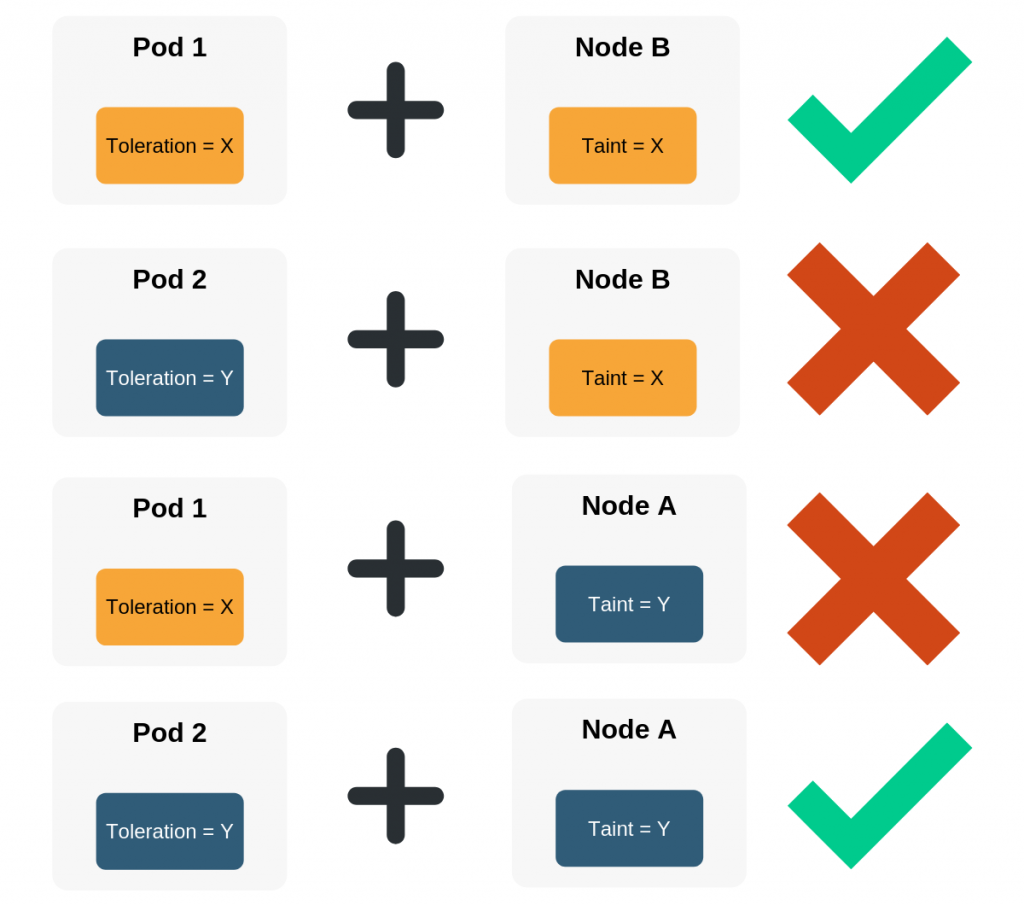
Taint
A taint is a key-value pair which prevents pods from being scheduled on nodes/node groups. Taints are specified on nodes
Toleration
A toleration is a key-value pair specified on pods which enables pods to be scheduled on nodes/nodegroups. Tolerations are specified on pods.
Taints and tolerations work together, the goal is to ensure that pods are only scheduled on appropriate nodes. If the toleration on the pod matches the taint on the node then the pod is allowed to be scheduled on that node. But, if the toleration on the pod does not match the taint on the node, then the node will not accept the pod.
Namespace
Namespaces are an abstraction used in Kubernetes. It allows you to have multiple virtual clusters within the same physical cluster. Each of these virtual clusters is a namespace.
Namespaces are only really useful if there are many users working with your Kubernetes cluster across multiple teams and projects. They can help you to organise and divide cluster resources. One main benefit is around names, object names only need to be unique within a namespace. So you can use the same name for objects across different namespaces.
Operational
So you’ve got a cluster up and running, with all the necessary components to identify and organise the various Kubernetes objects. But how does Kubernetes keep everything running smoothly? That’s where operational components come in!
Job
A job is a task that runs to completion.
The task is classed as complete when the required number of pods have completed and terminated. The job tracks the successful completions of the pods.
The simplest jobs run one pod to completion, the job will start a new pod if the original fails for any reason. But a job can also be used to run multiple pods in parallel.
Cronjob
Cronjob manages jobs which run on a schedule, it also allows you to add some specific parameters for how job failure should be handled.
 So, you can set up a cronjob to run one job every 5 minutes or to run a job for 60 minutes every day at set time periods, say 4 pm and 5.45 pm. This is great for tasks which need to be completed periodically, for example, if you have a recruitment app you might want to pull in the details of new applicants every 5 minutes.
So, you can set up a cronjob to run one job every 5 minutes or to run a job for 60 minutes every day at set time periods, say 4 pm and 5.45 pm. This is great for tasks which need to be completed periodically, for example, if you have a recruitment app you might want to pull in the details of new applicants every 5 minutes.
Some of the additional parameters you can apply include backoffLimit; which restricts the number of times a pod can restart if a job fails and startingDeadlineSeconds; which you can use to prevent a job from starting at all if it hasn’t automatically started within a specified time frame after the expected start time.
StatefulSets
Stateless applications generally make Kubernetes a lot easier, but there can be issues with data loss if a pod fails. StatefulSets helps to overcome this.
With StatefulSets, you can assign a pod a number, and assign resources to that number – such as volumes, network IDs and other indexes. So if a pod fails, it’ll be restored with the same data it had previously.
DaemonSet
A DaemonSet is used to deploy system daemons that power Kubernetes and the OS e.g. log collectors or node monitoring agents.
These system daemons are typically required on every node, so the DaemonSet ensures that a copy of these daemon pods is running on every node. When a new node is spun up, so is a new copy of the DaemonSet’s pods.
Probes
Probes check the liveness and readiness of containers within pods.
If a liveness probe detects an issue where an application is running but not making progress then it can restart a container to increase the applications’ availability.
Readiness probes check when a container is ready to start accepting traffic. A pod is ready once all of its containers are ready.
These probes enable exciting DevOps improvements – such as zero downtime deploys, preventing broken deploys and self-recovering containers.
Operators
Operators are deployed to a Kubernetes cluster and enable you to write an application to fully manage another.
An operator can monitor, change pods/services, scale the cluster up/down and even call endpoints in running applications. For example, an operator could detect if a pod is running at above 90% CPU and provision more resource automatically to keep it running.
Persistent Volumes
Persistent Volumes (PVs) are used for static provisioning, where storage has been created in advance.
So, when a new pod is created the author can request a PV which will reference an existing piece of storage space in the cluster. This storage space is then assigned to the pod. PVs persist beyond the lifecycle of individual pods. So when a pod is deleted, the storage it was using (and the PV that represents that storage) still exist.
PVs are useful because objects that run on your cluster will not run on the same node all the time, so they need somewhere to store data.
Storage Class
Storage classes are used to define the different storage types available on the cluster.
You can define various properties including the provisioner, volume parameters and reclaim policy. Storage classes are used alongside persistent volumes (PVs) so that users can access PVs with the correct properties for their storage needs, without being exposed to the explicit details of how those volumes are implemented.
Network Policy
The network policy specifies how pods can communicate with each other and with other network endpoints e.g. ports.
By default, all pods are non-isolated meaning they can connect to any other pod and accept traffic from any source. But, you can use the network policy to stop certain pods from connecting to each other and to reject traffic from certain ports. The network policy uses labels to group the pods and define the specified rules for each group.
Ingress

Ingress is the ‘door’ to your Kubernetes cluster. It is an API object that allows external traffic to access the services in your cluster.
For example, you could have a web ingress allowing port 80 traffic to your application. As it is responsible for external traffic, Ingress can provide load balancing.
CustomResourceDefinition
A custom resource definition (CRD) allows you to extend the Kubernetes API beyond the built-in resources without having to build a full custom server.
So by default in the Kubernetes API, there is a built-in pods resource which stores all of the pods in your cluster. By using a CRD, you can create a new resource to store custom objects which you have defined.
To create a CRD you simply create a YAML file containing the necessary fields. When you deploy the CRD file into the cluster, the API will then begin serving the new custom object.
Resource Quota
Resource quotas are applied to namespaces to constrain their resource consumption.
Two main limits are set. Firstly, on the quantity of each type of object e.g. pods or services that can be created in each namespace. Secondly, on the total compute resources that can be consumed by objects in that namespace.
Horizontal Pod Autoscaler (HPA)
HPA is an API resource which automates pod replication.
It automatically scales the number of pod replicas running at any given time to reach CPU utilization targets or based on information from the ReplicationController about the replicas needed for the application to move towards its desired state.
Tools & Plugins
Kubernetes already has an impressive amount of functionality built-in, however, there are a variety of tools and plugins you can use alongside Kubernetes to get more out of it. Some of the most popular tools are explained below:
Container Storage Interface (CSI)
The CSI provides a standard interface between storage systems and containers.
The CSI is what enables custom storage plugins created by other vendors to work with Kubernetes without needing to add them to the Kubernetes repository.
Container Network Interface (CNI)
The CNI provides a standard interface between network providers and Kubernetes networking.
Kubenet is the default network provider in Kubernetes, it is generally pretty good but it is basic. The CNI allows you to use other network providers which offer more advanced features e.g. BGP and mesh networking if this is something you need for your cluster.
Helm
Helm is an application package manager which runs on top of Kubernetes.
 It allows you to describe your application structure using helm charts and manage the structure using simple commands. The tool allows you to clearly define each microservice within your application and only scale the necessary ones (by spinning up more pods and nodes in Kubernetes as needed).
It allows you to describe your application structure using helm charts and manage the structure using simple commands. The tool allows you to clearly define each microservice within your application and only scale the necessary ones (by spinning up more pods and nodes in Kubernetes as needed).
Tiller
Tiller is the “in-cluster” portion of Helm which interacts directly with the Kubernetes API to allow you to add, upgrade, query or delete Kubernetes resources using Helm.
Ceph
![]() Ceph is a distributed storage system created with scalability in mind. It is an example of a custom storage plugin that you can use with Kubernetes.
Ceph is a distributed storage system created with scalability in mind. It is an example of a custom storage plugin that you can use with Kubernetes.
You can use Helm to deploy Ceph in a Kubernetes environment to add durable storage.
Prometheus
Prometheus is a solution for monitoring metrics on Kubernetes. It is a great tool if you are looking to scale your Kubernetes cluster.
![]() Prometheus runs on top of Kubernetes and provides a metrics dashboard which your team can use to proactively monitor your cluster. You can also set it up to trigger alerts and notifications for certain metrics.
Prometheus runs on top of Kubernetes and provides a metrics dashboard which your team can use to proactively monitor your cluster. You can also set it up to trigger alerts and notifications for certain metrics.
Istio
Istio is a tool for connecting, monitoring and securing microservices.
 It can be deployed on Kubernetes to help your development team handle traffic management, load balancing, access control and more for your containerised application.
It can be deployed on Kubernetes to help your development team handle traffic management, load balancing, access control and more for your containerised application.
Of course, there are many other tools which can be used with Kubernetes, we’ve just covered some of the most popular currently.
Anything to Add?
We are planning to update this article as more features, components and tools become available. Are there any terms you’d like to see added? Get in touch and let us know.
Or, if you’d rather forget about Kubernetes terminology all together and focus on actually developing software & services, we can help with that too! Bytemark now offers end-to-end Kubernetes management. Find out more and register to discuss your options.